
It’s important to keep in mind that an event might include a wide variety of specifics about the actions and efforts required to complete a task or project. Events are processed as collections of key-value pairs, where the value in each pair is a representation of some aspect of the event. Dataset is shorthand for “set of events.” Each and every facet of an event can be represented in the dataset as either a column or a dimension.
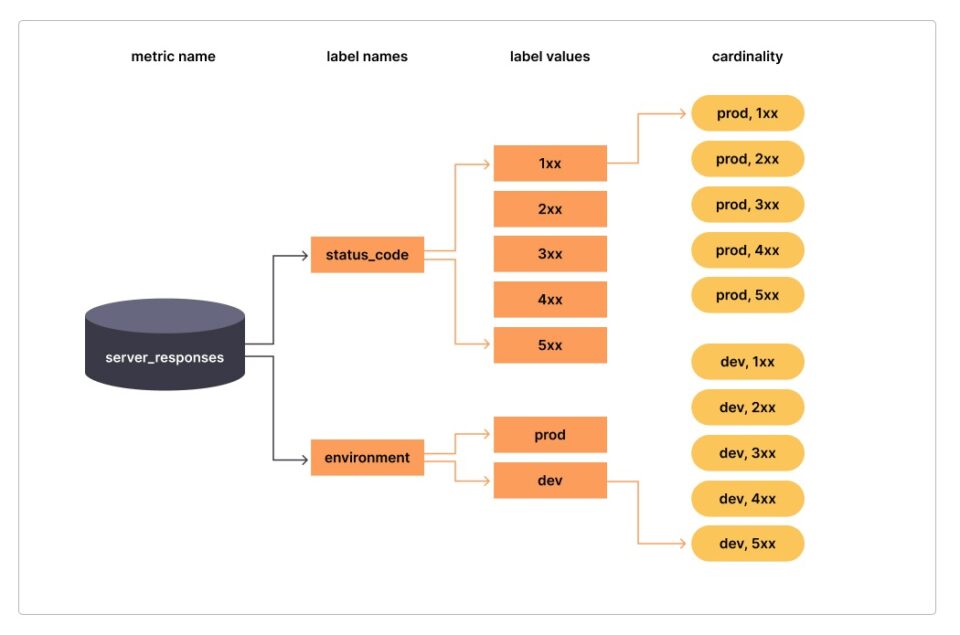
The idea of high cardinality refers to the presence of numerous alternative values for a single property, whereas “high dimensionality” alludes to the occurrence of multiple separate qualities linked with events. It can be quite expensive for many database designs to store and query data with a large cardinality and/or a high number of dimensions. It is designed in such a way that users have complete freedom in how they frame their queries. The cardinality of the properties used to form groups or filters is up to the discretion of the user. Let’s take a closer look at them.
How Would You Define Cardinality?
When discussing data attributes, the term “cardinality” refers to the maximum number of distinct values the attribute can take on. A boolean column, which can only store the values true or false, has a small cardinality since there are only two potential states. There may only be a handful of possible values for HTTP status codes like 200, 301, 302, 404, and 500. Low cardinality data like AWS Zone, code version, and URL might be useful for tracking system-wide trends and patterns.
If a column can take on a wide variety of values, that its cardinality is high. There can be hundreds of thousands of unique values in columns like user Id, shopping Cart Id, and order Id in an e-commerce system. In a similar vein, request Id may easily climb into the millions. A high-cardinality URL column can be the result of a large number of GET query parameter permutations. The ability to narrow down the individual causes that contributed to the problem is substantially facilitated by working with a field that has a high cardinality.
Both High Cardinality and High Dimensionality Play Key Roles in Assuring Observability
One aspect of observability is the speed and efficiency with which fields containing a large number of different values can be examined. One user’s actions within the dataset are responsible for the issue. Unfortunately for one user, they stumbled into an API endpoint that responded painfully slowly. The scope of the endpoint’s wrongdoing and the people harmed might be understood with greater clarity thanks to the ability to correctly distinguish the specific endpoint and user.
It allows for queries to be run on fields with a large number of possible values. It is possible to tailor an investigation into an error report by analysing the events that were generated to meet the needs of the reporting user. It is even feasible to do queries on multiple dimensions, such as duration, to particularly look for events that are characterized by their fast-running nature.
It can also be useful for storing fields of smaller cardinality, such as error messages. You may save information like “error message” alongside other fields. When you need to know how often “cannot connect”-related error messages occur, being able to query this data is a great help.
Conclusion
The query engine effectively mixes and organizes the data for analysis, allowing for the hassle-free management of large, complicated datasets at low cost and with high throughput.